
An Introduction to YAML
Unleashing the Potential of YAML: A Versatile and Readable Data Serialisation Format


Introduction
YAML stands for "YAML ain't markup language" (recursion acronym). It is a language used to store data and represent it in a format that is readable and serialized.
It used to be called "Yet another markup language". Why? Because it was created at a time when markup languages were at the forefront of connectivity and data visualization.
With due time, it became a common misconception about how it functions. It was recognized as more data-oriented rather than just a document markup. Hence it was changed to "YAML ain't markup language".
Well, if you are guessing what a markup language is? It is nothing but the way how you structure pages or documents by adding different elements like tags, headers, lists, components, and so on. A good example is HTML!
What is YAML exactly?
As mentioned earlier, it provides us with a format that helps us to visualize and store data in a simple way that is easier to read. It is similar to XML and JSON files. It also performs data serialization and deserialization.
what does it mean?
Serializing data is converting objects (code + data) into a machine-readable (common standard) format (streams of bytes) that can be transmitted and understood by various computer environment applications. Deserialization is just the opposite. It is just extracting the necessary information for us to visualize the code.
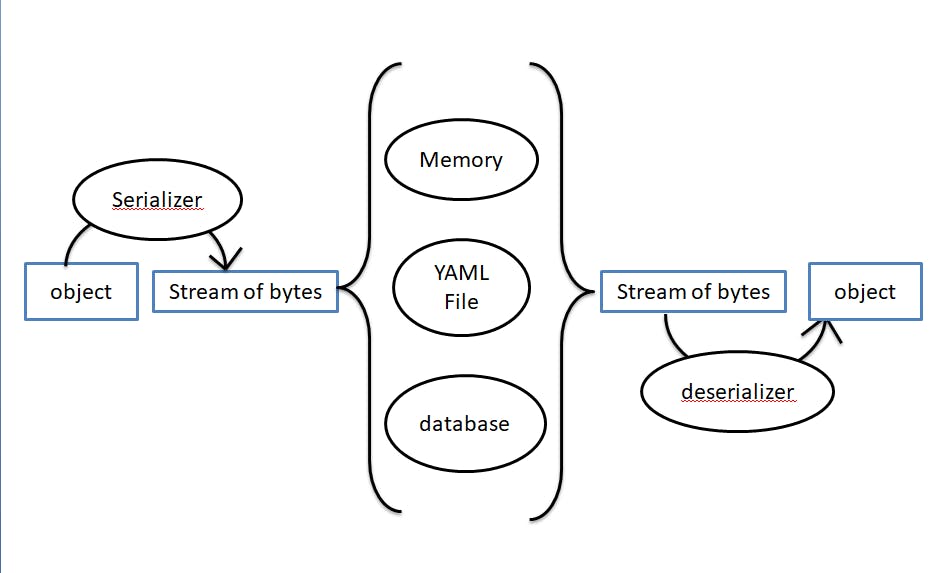
Let's understand with the help of an example.
A developer writes a few lines of code for an Android application. Now he thinks to scale to various applications like web apps, websites, and so on. So he needs to write code or a configuration file in such a way that it can be understood by all of them. He can achieve this by implementing data serialization.
Why YAML?
The configuration files for Docker, Kubernetes, Ansible, Prometheus, all are written in YAML. Hence it is a widely used format for writing configurations and manifests for many DevOps tools and applications.
Let's say you created some applications and you want to run a few of them on these many servers on the cloud. So Kubernetes will create an object or a pod that will run those applications. But first, you need to provide a configuration file or a YAML file that tells Kubernetes what your object containing the application should look like.
What are its benefits?
It is simple and easy to read.
It gives high importance to syntax, indentation being one of them.
It can be converted to JSON, XML, etc.
Most languages use YAML.
YAML files can be easily shared and used across different platforms and operating systems without requiring any special software or tools.
It is widely used in configuration files for software applications, build systems, continuous integration/continuous deployment (CI/CD) pipelines, and infrastructure-as-code (IaC) tools like Ansible, Terraform, Docker Compose, orchestration tool like Kubernetes and so many out there.
It is more powerful when representing complex data.
There are libraries and parsers available for most popular programming languages to work with YAML.
Parsing is easy.
Hands-on understanding
Let's have a brief understanding of how YAML code is structured and written.The syntax of a YAML code is very simple. It is written in key-value pairs.
Scalars
The first type of data that can be written in YAML is scalars. These include strings, numbers, booleans, null, timestamps, etc.
A string is a collection of characters that can be anything. There are 5 ways to write a string -
Double quotes (")
Single quotes (')
No quotes (plain)
Folded strings (>)
Multiple line strings (|)
"name": "xyz"
name: 'xyz'
name: xyz
Code becomes messy when a single line becomes long enough to scroll sideways. To prevent this, the symbol ">" can be added to let the compiler know that even if we are breaking a single line of code into multiple lines, it should treat it as a single line. This is how folding is done.
description: >
This is a long description
that spans multiple lines
in YAML.
And when you want your lines of code to be treated exactly as mentioned even if they are folded into multiple lines, we can use the pipe symbol (|).
message: |
This is a multiline
string in YAML.
Line breaks and spacing
are preserved as is.
Since we know what a string looks like in YAML, let's move on to other scalars. Some self-explanatory examples are...
"mammals": "humans" # string
name: John Doe # String
---
age: 25 # Number -> integer
marks: 98.3 # float
exponents: 78E56 # exponent number
notANum: .nan # not a number
---
isStudent: true # Boolean alternatives -> TRUE, yes, YES, on, ON
canFly: false # FALSE, no, NO, off, OFF.
---
score: null # Null value
timestamp: 2023-06-03T10:15:00Z # Timestamp
datatypes can be explicitly specified by mentioning "!! (datatype)" in front of the value...
---
# integer numbers
zero: !!int 0
positiveNumber: !!int 67
negativeNumber: !!int -90
binaryNum: !!int 10011
octalVal: !!int 0342
hexaVal: !!int 0x46
commaValue: !!int +69_000 # 69,000
---
# floating point numbers
marks: !!float 86.3
infinite: !!float .inf
---
# boolean
canRun: !!bool No
canFly: !!bool Yes
---
# string
name: !!str xyz
---
# null
haveKids: !!null null # or NULL or ~
---
# timestamp
defaultTime: !! timestamp 2023-06-03T10:15:00Z # UTC time
IndiaTime: !! timestamp 2023-06-03T10:15:00Z +5:30 # gives India Time
List
The second one is a list or a map. In YAML, it represents an ordered collection of values. Each item starts with a hyphen. Each item can be of any YAML data type, including scalars, lists, or dictionaries. This is how you can write down a list of things...
- apple
- banana
- orange
- mango
A list can be written in a block style referring to a key element.
supercars:
- Lamborghini
- Buggati
- Aston Martin
- Audi
- Mercedes
...make sure you space them out properly because YAML has a very strict indentation rule.
Let's say, it becomes irritating to take care of the indentation problem, you can add the components of the above list separated by commas between square brackets.
This is called the float style.
supercars: [Lamborghini, Buggati, Aston Martin, Audi, Mercedes]
Lists can also be explicitly sequenced by using the "!!seq" tag as follows..
supercars: !!seq
- Lamborghini
- Buggati
- Aston Martin
- Audi
- Mercedes
A list can also have one or two items missing. In this case, it is called a sparse sequence or a sparse list.
supercars:
- Lamborghini
-
- Aston Martin
-
- Mercedes
Nested sequence of lists....
- apple
- banana
- orange
- mango
-
- Lamborghini
- Buggati
- Aston Martin
- Audi
- Mercedes
In the above example, we have a nested sequence of lists with the first list of fruits and the second list of supercars.
'!!pairs' is a tag used to represent a sequence of key-value pairs. It helps to assign a key to have multiple values..
specs: !!pairs
- car1: red
- car1: 4-wheel drive
'!!set' allows to have unique values...
values: !!set
? value1
? value2
? value3
Dictionary
The third one is a dictionary. It is an object giving information about various types of data represented by the key element. The key is of string data type, whereas the value can be of any type. We can say that a dictionary is an unordered list of component features.
car:
brand: Lamborghini
model: Aventador SVJ
year: 2023
top_speed: 217 mph
body_style: Coupe
color: Arancio Atlas (Orange)
features:
- Carbon fiber body panels
- Active aerodynamics
- Adaptive suspension
- Ceramic brakes
price: $517,770
It can also be typed in the flow notation like this..
car:
brand: Lamborghini
model: Aventador SVJ
year: 2023
keyFeatures: { top_speed: 217 mph, body_style: Coupe }
'!!omap' allows us to have an ordered map or dictionary..
fruits: !!omap
- apple: red
- orange: orange
- banana: yellow
The next one is nested data types. A YAML file can have lists and dictionaries nested within another list or dictionaries.
In the following code, we can see that we have a list of fruits, each being a dictionary (name, color, nutrients). And each dictionary contains a list of nutrients the fruit gives.
fruits:
- name: apple
color: red
nutrients:
- vitamin C
- fiber
- name: banana
color: yellow
nutrients:
- vitamin B6
- potassium
- name: orange
color: orange
nutrients:
- vitamin C
- folate
Different types of documents can be separated by 3 dashes like this " --- ", and to end your document, add "..." , for ex.
---
- name: John Doe
age: 25
isStudent: true
- brand: Apple
product: iPhone
price: 999
---
title: My Todo List
tasks:
- task: Buy groceries
priority: high
- task: Pay bills
priority: medium
...
In the above example, we see that the first doc. is a list of dictionaries (John Doe and Apple), whereas the second doc. represents a dictionary key-value pair and a list of tasks each being a dictionary within.
The code can be commented simply by putting a hash symbol (#) in front of the line like this..
colors:
- red
# - blue
- green
# - pink
Anchors and Aliases
These help to reuse properties in YAML using symbols &, <<, and * . '&' is used to define anchors, '<<' to merge properties, and '*' to create aliases allowing us to reuse data.
# Define an anchor using &
person: &person_details
name: John Doe
age: 30
# Use the << to merge additional properties with the anchored values
customer:
<<: *person_details
email: johndoe@example.com
# Another alias referencing the same anchored values
employee: *person_details
age: 26
In this example, we define an anchor named person_details first using &, then with the anchor name (&person_details). The anchor is used in a dictionary that contains a person's name and age.
Then, in the 'customer' section, we use the '<<' syntax to combine the anchored values with extra characteristics. The '<<' makes sure that the 'person_details' anchor's properties should be combined with the current dictionary. As a result, the 'customer' dictionary will include the 'person_details' anchor's 'name' and 'age' properties, as well as the extra 'email' property.
Finally, we use 'person_details' to construct an alias called 'employee'. The '*' character followed by the anchor name (*person_details) generates an alias that refers to the anchored values. As a result, the 'employee' dictionary will have the same 'name' and 'age' properties. One additional thing happening over here is, the property 'age' is being overridden with the value 26.
Comparison among YAML, JSON, and XML
Like YAML, JSON (Javascript Object Notation) too performs its way of representing data in a key-value format. Except for the fact that it has a stricter syntax which includes spaces, indentation, mandatory double quotes in keys and values, and most importantly curly brackets.
On the other hand, XML (Extensible Markup language) uses tags like HTML to show data.
Let's have a look at the tree representation of a person. He has a name, age, and address. The address in turn contains street and city properties. (As simple as that)
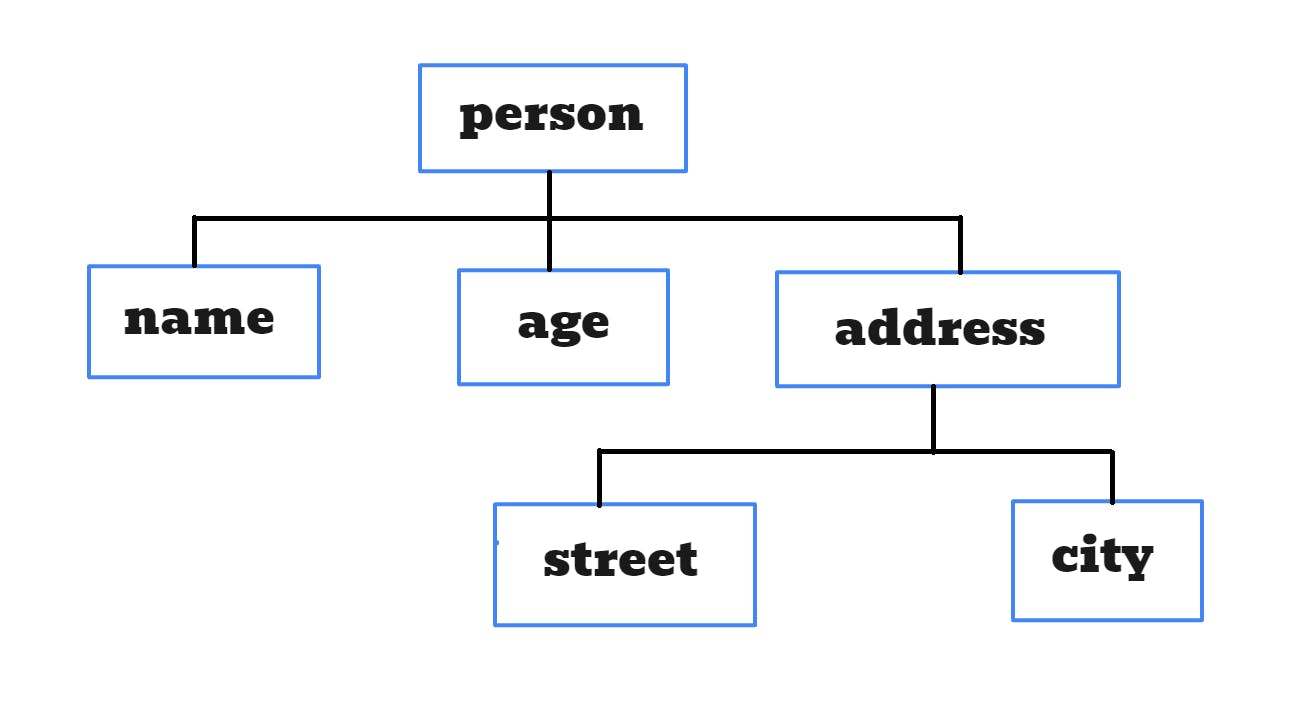
Let's compare them code-wise...
person:
name: Alex
age: 30
address:
street: 123 Bridgeton lane
city: Brooklyn
{
"person": {
"name": "Alex",
"age": 30,
"address": {
"street": "123 Bridgeton lane",
"city": "Brooklyn"
}
}
}
<person>
<name>Alex</name>
<age>30</age>
<address>
<street>123 Bridgeton lane</street>
<city>Brooklyn</city>
</address>
</person>
YAML from a technical perspective
Let's see how YAML works in a real-world scenario.
Ansible
Ansible, a prominent IT automation and configuration management tool, frequently employs YAML. YAML is used in Ansible to define playbooks, which are high-level descriptions of a system's desired state.
Ansible playbooks are used to automate repetitive operations that execute actions automatically.
Down below we have an Ansible playbook that installs Nginx, replaces the existing default Nginx landing page with the supplied template, and ultimately allows TCP access on port 80.
---
- hosts: all
become: yes
vars:
page_title: Spacelift
page_description: Spacelift is a sophisticated CI/CD platform for Terraform, CloudFormation, Pulumi, and Kubernetes.
tasks:
- name: Install Nginx
apt:
name: nginx
state: latest
- name: Apply Page Template
template:
src: files/spacelift-intro.j2
dest: /var/www/html/index.nginx-debian.html
- name: Allow all access to tcp port 80
ufw:
rule: allow
port: '80'
proto: tcp
Kubernetes
YAML is widely used in Kubernetes as the preferred format for specifying and configuring various cluster resources. Users can declare the attributes, behavior, and relationships of Kubernetes resources using YAML files, which serve as a declarative representation of the desired state of objects.
Kubernetes operates on a state model, attempting to attain the desired state declaratively from the present state. Kubernetes defines the Kubernetes object with YAML files, which are then applied to the cluster to build resources such as pods, services, and deployments.
Kubernetes is a container orchestrator which does more than that including deployment, scaling, and management of containerized applications.
Here is an example of a YAML file that describes a resource kind "deployment" that runs an app "my-app" with 3 replicas of it.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app-container
image: my-app-image:latest
ports:
- containerPort: 8080
GitLab CI/CD
GitLab is a DevOps platform that is web-based and offers a full collection of tools for managing the entire software development lifecycle. It includes tools for teams to interact, version control their code, automate CI/CD pipelines, track bugs, manage repositories, and deploy apps.
Here is an example of YAML's contribution to building CI/CD pipelines.
stages:
- build
- test
- deploy
variables:
IMAGE_TAG: "latest"
build_job:
stage: build
script:
- docker build -t my-app:${IMAGE_TAG} .
- docker push my-app:${IMAGE_TAG}
test_job:
stage: test
script:
- docker run my-app:${IMAGE_TAG} npm test
deploy_job:
stage: deploy
script:
- kubectl apply -f deployment.yaml
The YAML file in this example describes a pipeline with three stages: build, test, and deploy. Each level has a job that completes particular responsibilities.
The "variables" section defines an "IMAGE_TAG" variable with the value "latest" that may be used throughout the pipeline.
The "build_job" class represents a job in the build stage. It creates a Docker image for a given project, tags it with the "IMAGE_TAG" variable, and uploads it to a container registry.
The "test_job" class represents a job in the testing stage. It executes the project's tests and runs the Docker image built during the build step.
The "deploy_job" class represents a job in the deployment stage. It employs the Kubernetes deployment settings specified in the "deployment.yaml".
Conclusion
YAML provides a robust and user-friendly means of representing and exchanging data. Because of its readability, versatility, compatibility, and integration capabilities, it is a popular choice in a variety of disciplines, including configuration files, data serialization, and system orchestration. Developers can improve productivity, code maintainability, and cooperation within their projects by exploiting YAML's features.